

Visual Dialog Challenge 2018
Overview
We are pleased to announce the first Visual Dialog Challenge!
Visual Dialog is a novel task that requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Specifically, given an image, a dialog history (consisting of the image caption and a sequence of previous questions and answers), the agent has to answer a follow-up question in the dialog. To perform well on this task, the agent needs to ground the query not only in the visual content but also in the dialog history.
We believe that the next generation of intelligent systems will need to posses this ability to hold a dialog about visual content for a variety of applications, and we encourage teams to participate and help push the state of the art in this exciting area!
Winners' announcement + analysis: #winners
Leaderboard: #leaderboard
Dates
04 Jun 2018 — Visual Dialog Challenge 2018 announced!30 Jun 2018 — VisDial v1.0 and evaluation server on EvalAI released!
09 Jul 2018 — Starter code in PyTorch released!
12 Jul 2018 — Evaluation using dense annotations now available on EvalAI!
15 Aug 2018 (23:59:59 GMT) — Submission deadline for participants.
08 Sep 2018 — Winners' announcement at SiVL Workshop, ECCV 2018, Munich.
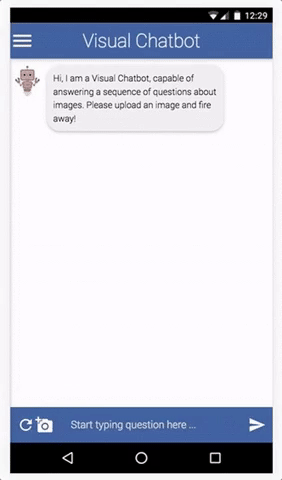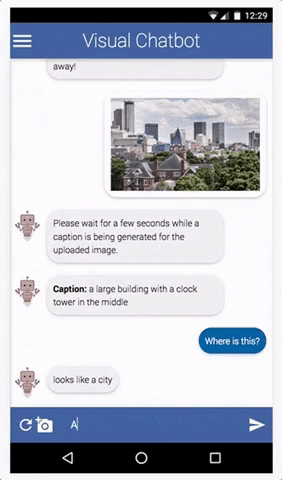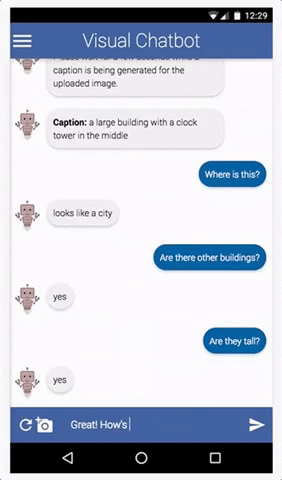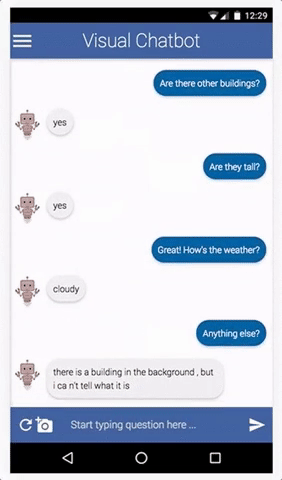
Dataset Description
The challenge will be conducted on v1.0 of the VisDial dataset, which is based on COCO images. With this release of v1.0, we are moving away from v0.9, the version of the dataset most prior works have been benchmarking results on.
VisDial v1.0 contains 1 dialog with 10 question-answer pairs (starting from an image caption) on ~130k images from COCO-trainval and Flickr, totalling ~1.3 million question-answer pairs.
The v1.0 training set consists of dialogs on ~120k images from COCO-trainval, while the validation and test sets consist of dialogs on an additional ~10k COCO-like images from Flickr.
We have worked closely with the COCO team to ensure that these additional images match the distribution of images and captions of the training set.
Note that the v1.0 training set combines v0.9 training and v0.9 validation splits collected on COCO-train2014 and COCO-val2014 images respectively.
See FAQ below for more details on splits.
The download links and more information on data format can be found here.
Participation Guidelines
To participate, teams must register on EvalAI and create a team for the challenge (see this quickstart guide).
The challenge page is available here: evalai.cloudcv.org/web/challenges/challenge-page/103/overview.
The challenge has three phases:
| Phase | #(Images) x #(Dialog rounds) | Submissions | Results | Leaderboard |
|---|---|---|---|---|
| val | 2,064 x 10 | unlimited | immediate | none |
| test-std | 4000 x 1 | 5 total | immediate | public (optional) |
| test-challenge | 4000 x 1 | 5 total | announced at ECCV 2018 | private, announced at ECCV 2018 |
While answers are already provided for the val set, this phase is useful for sanity checking result format without wasting submissions in the other phases. For the test-std and test-challenge phases, the results must be submitted on the full test set. By default, the submissions for test-std phase are private but can be voluntarily released to the public leaderboard, with a limit of one public leaderboard entry per team. Submissions to test-challenge phase are considered entries into the challenge. For multiple submissions to test-challenge, the approach with the highest test-std accuracy will be used.
It is not acceptable to create multiple accounts for a single team in order to bypass these limits. The exception to this is if a group is working on multiple unrelated methods, in this case all sets of results can be submitted for evaluation. Results must be submitted to the evaluation server by the challenge deadline -- no exceptions will be made.
Starter code
- Lua Torch implementation: @batra-mlp-lab/visdial
- Starter code in PyTorch: @batra-mlp-lab/visdial-challenge-starter-pytorch
The Lua Torch implementation supports all models from the Visual Dialog paper. PyTorch starter code comes with Late Fusion (LF) Encoder - Discriminative Decoder support. Both of these codebases include dataloaders for VisDial v1.0, pretrained models, scripts to save model predictions in the challenge submission format, as well as code to train your own models.
Submission Format
To submit to a phase, teams must upload a JSON file containing their model's answer rankings in the following format:
[{
'image_id': int,
'round_id': int,
'ranks': [int x100]
}, {...}]ranks is an array of ranks 1-100 for each of the 100 candidate answers with the first entry corresponds to the rank of the first candidate answer. We provide an example submission file here (from the Late Fusion + Attention model from the Torch codebase). When submitting, teams should also include a method name, method description, project URL, and publication URL if available.
Evaluation
For evaluation, we have the following:
- Retrieval metrics / evaluation using sparse annotations: We have mean reciprocal rank (MRR), recall (R@{1, 5, 10}), and mean rank as described in the Visual Dialog paper. Evaluation through these metrics is carried out for all the three challenge phases.
- Evaluation using dense annotations: As some of the candidate options may be semantically identical (e.g. 'yeah' and 'yes'), we have had four human annotators indicate whether each of the 100 candidate answers is correct for each test phase instance. For evaluation, we report the normalized discounted cumulative gain (NDCG) over the top K ranked options, where K is the number of answers marked as correct by at least one annotator. For this computation, we consider the relevance of an answer to be the fraction of annotators that marked it as correct.
Challenge winners will be picked based on the NDCG evaluation metric.
NDCG is invariant to the order of options with identical relevance and to the order of options outside of the top K. Here is an example:
Consider five answer options with ranking (from high to low): ["yes", "yes it is", "probably", "two", "no"],
their corresponding ground truth relevances: [1, 1, 0.5, 0, 0 ],
such that the number of relevant options, i.e. options with non-zero relevance, or K, is 3.
Here, NDCG remains unchanged for two cases:
- Swapping options with same relevance.
Ranking NDCG ["yes", "yes it is", "two", "probably", "no"]0.8670 ["yes it is", "yes", "two", "probably", "no"]0.8670 - Shuffling options after first K indices.
Ranking NDCG ["yes", "two", "yes it is", "probably", "no"]0.7974 ["yes", "two", "yes it is", "no", "probably"]0.7974
Download dense annotations on a small subset of v1.0 train
Relevance scores from these dense annotations on a small subset of 2000 images (200 instances per round x 10; 2 human annotators per instance) from VisDial v1.0 train are available for download here. Annotations for the test split will not be released.
Winners' announcement and analysis
Winning teams of the Visual Dialog challenge 2018 were announced at the SiVL workshop at ECCV held in Munich, Germany.
Slides from the presentation are available here, and includes analysis of submissions made to the challenge.
Photos from the event:




Leaderboard
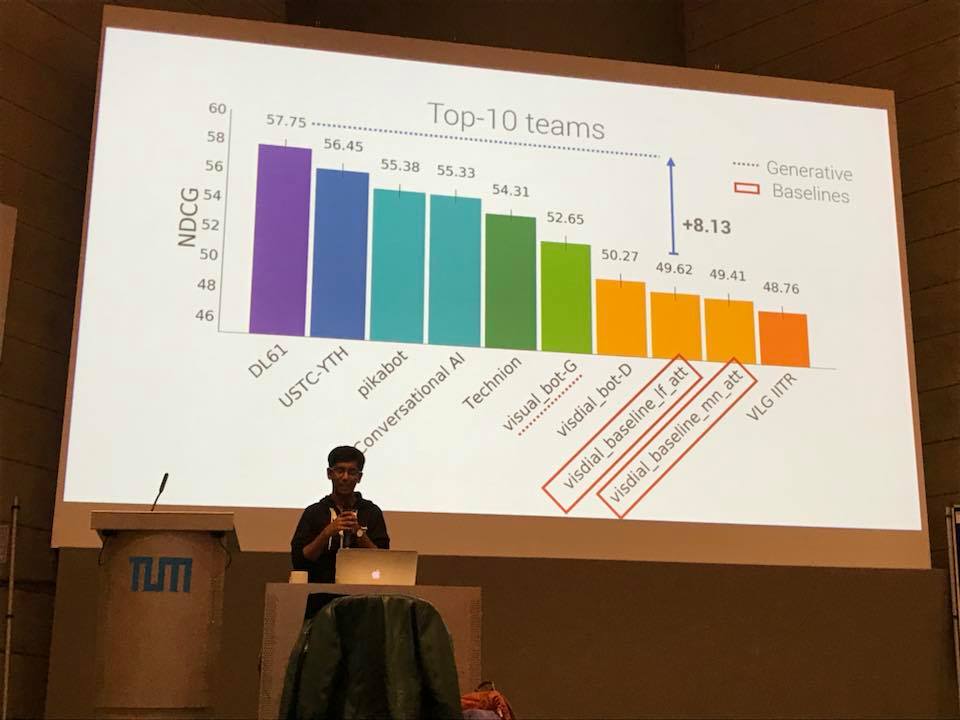
NOTE: Winners were picked based on NDCG on the complete test split.
| Position | Team | NDCG | MRR | R@1 | R@5 | R@10 | Mean Rank |
|---|---|---|---|---|---|---|---|
| 1 | DL61 [Slides] | 57.75 | 64.54 | 50.40 | 82.19 | 91.40 | 3.81 |
| 2 | USTC-YTH [Slides] | 56.45 | 62.82 | 49.16 | 79.41 | 88.76 | 4.43 |
| 3 | pikabot | 55.38 | 65.01 | 51.20 | 82.09 | 90.91 | 3.94 |
| 3 | MS Conversational AI | 55.33 | 64.68 | 51.18 | 81.38 | 90.50 | 3.97 |
| 5 | Technion | 54.31 | 68.14 | 54.24 | 85.26 | 93.09 | 3.45 |
| 6 | visual_bot-G | 52.65 | 50.63 | 38.35 | 63.08 | 74.21 | 9.80 |
| 7 | visdial_bot-D | 50.27 | 59.73 | 45.59 | 76.91 | 86.54 | 5.00 |
| 8 | VLG IITR | 48.76 | 60.06 | 45.88 | 76.71 | 87.11 | 4.79 |
| 9 | visual_dialog | 47.79 | 62.55 | 43.48 | 75.58 | 86.17 | 5.19 |
| 10 | SNU-BIVTT | 45.78 | 60.20 | 44.46 | 79.88 | 90.96 | 3.96 |
| 11 | Dream Team | 31.75 | 31.80 | 13.14 | 55.09 | 78.94 | 8.01 |
Frequently Asked Questions (FAQ)
- Why aren't the val and test sets the same as COCO?
- Conversations in Visual Dialog are seeded with captions, and releasing captions for COCO test images would compromise integrity of the COCO benchmarks. Hence, we have worked closely with the COCO team to ensure images for our evaluation splits are distributed similarly to the training set.
- Why are only single rounds evaluated per image in the test set?
- As the task is set up, agents must see the dialog history before answering questions -- making it impossible to test agents on more than one round per dialog without giving away the answers to other questions. We have sampled rounds uniformly for testing and will provide analysis at the workshop.
- Why is there only one track? Won't discriminative models dominate competition because it is based on ranking a set of options?
-
We considered having two tracks -- one for generative models and one for
discriminative models. But the distinction between the two can get blurry (e.g., non-parametric models that internally
maintain a large list of answer options), and the separation would be difficult to enforce in practice anyway.
So for now, we have a single track. Note that our choice of ranking for evaluation isn't an endorsement of either
approach (generative or discriminative) and we welcome all submissions.
[Update] Empirical findings from the 1st Visual Dialog Challenge indicate that generative models perform comparably (or even better sometimes) than discriminative models on the NDCG metric -- for example, 53.67 vs. 49.58 on VisDial v1.0 test-std for Memory Network + Attention with generative vs. discriminative decoding respectively. Code and models available here. - Isn't evaluation on the first round just VQA?
- Not quite! Even at the first round, agents are primed with a caption for the image and questions often refer to objects referenced in it.
- Why doesn't EvalAI report NDCG for val phase?
- NDCG is calculated using dense annotations for answer options. This makes evaluation more robust, but collecting these annotations is expensive and time-consuming. So for now, we have collected these for the test split — kept private and used for evaluation on EvalAI — and a small subset of the train split — available here. Participants are free to use the annotations on train to set up their own cross-validation routines.
- I don't see my question here, what do I do?
- Ping us on Discord, or email us at [email protected]!
Organizers

Georgia Tech

Georgia Tech

Georgia Tech

Carnegie Mellon

Georgia Tech

Georgia Tech

Georgia Tech, FAIR

Georgia Tech, FAIR
Acknowledgements
We thank organizers of the SiVL Workshop at ECCV 2018 for hosting the winners' announcement for this challenge.
Sponsors
This work is supported by grants awarded to Dhruv Batra and Devi Parikh.